![<?echo $_SERVER['SERVER_NAME'];?>](/template/twentyseventeen/skin/images/header.jpg)
Recently, I was invited to share what I learned in the NLP field at the O'Reilly Artificial Intelligence Conference in Beijing. I had the privilege of attending a training session on deepening learning organized by Unity Technologies. This conference led by Arthur Juliani gave me a lot of inspiration. I will share my achievements below.
In our conversations with major companies, we discovered many interesting applications, tools, and results of deep learning. At the same time, the application of deep reinforcement learning (such as AlphaGo) is often very esoteric and difficult to understand. In this article, I will introduce the key points of deep reinforcement learning in an easy-to-understand way.
The rise of deep reinforcement learning
There have been a lot of research achievements in the field of deep reinforcement learning, such as letting computers learn Atari games, defeating human players in Dota2, or defeating the world's top Go players. Unlike the traditional deep learning problem, which only focuses on cognition, deep reinforcement learning has added actions that can affect the environment, one dimension more than traditional. For example, traditional deep learning solves the problem of “is there a stop sign in this painting?†and deep reinforcement learning will also study the question “where does the destination go and how should it arrive?â€. For example, in a dialogue system, the purpose of traditional deep learning is to find the correct answer to the corresponding question. Depth-enhanced learning pays attention to how to combine the correct sentence order to get a positive result. For example, how to answer can make customers happy.
This makes deep reinforcement learning very popular in tasks that require early planning and adaptation, such as manufacturing or autonomous driving. However, the practical application of the industry cannot catch up with the theoretical development. The main reason is that deep reinforcement learning often requires an agent to perform millions of experiments. If you want to achieve this quickly, you need a simulation environment. Here you can refer to Unity's tutorial to create a simulation environment.
Next, I will describe in detail some of the current mainstream algorithms for deeper learning.
From slot machines to video games, talking about reinforcement learning
Depth-enhanced learning can defeat top Go players, but to figure out how it is done, first of all, learn a few simple concepts. Let's start with a simple one.
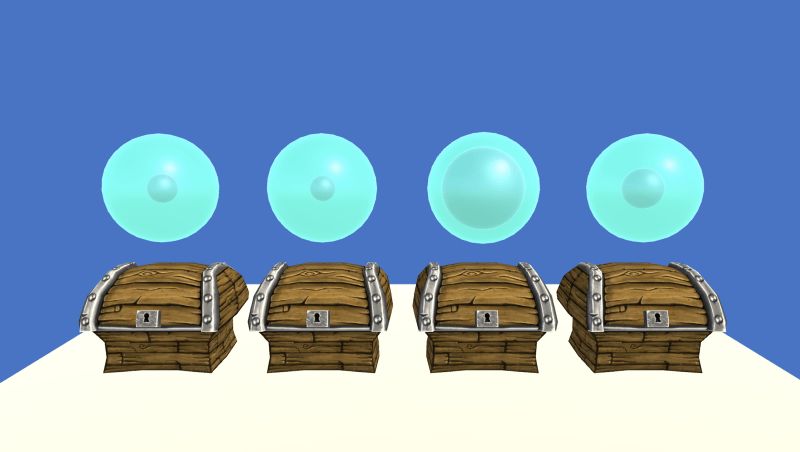
Suppose you have four boxes in front of you. You can only open one box at a time, and the money (rewards) in each one is different. Your goal is to get the maximum amount of money in a certain number of games. This classic game is known as the "multi-armed bandit problem." The core of this problem is to control the number of games while using the known information to select the best object.
Here we need to use a Q function that maps behaviors to expected rewards. First, we set all the Q values ​​the same. Then, we will update the Q after each box selection, based on how much money is in the box. This allows us to learn a good value function. We use a neural network to estimate the potential performance of the Q function on the four boxes.
The cost function tells us how each outcome is predicted and the strategy is a function that decides at which step to stop. In other words, we may choose the strategy with the highest Q value. However, this is very bad in practice, because the estimate of Q is very ridiculous at the very beginning and is not enough to account for trial and error experience. This is why we need to add a mechanism to the strategy to encourage exploration. One of the methods is to use a greedy algorithm that uses a probability ε for random selection. Initially, when the probability is close to 1, the choice is more random. As the probability decreases, you will learn more about the box. In the end we knew it was better.
In practice, we may want to choose another, more subtle method without randomly selecting or selecting the best strategy. One of these methods is Boltzmann Exploration, which can change the probability according to the current situation and add a random factor.
How will it be in different states?
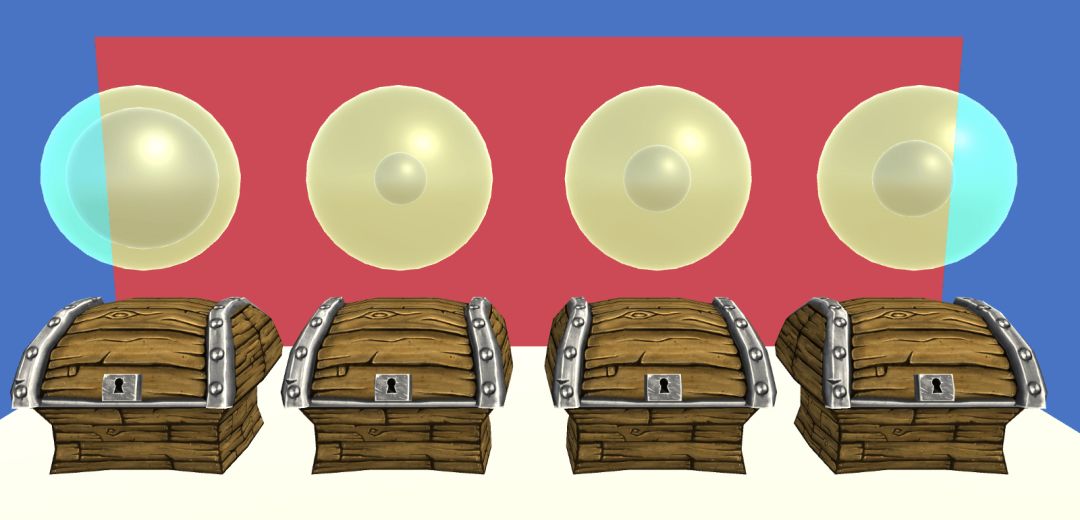
Different background colors here represent different average rewards
The background of the previous example assumes that the states are the same, picking four identical boxes. The more real situation is very different and there are different states. Now that the background behind the box is constantly changing between the three colors, the value of each box is changing. So we need to learn a Q function to determine the box selection and background color. This problem is called "the issue of multi-armed gambling machines in context."
The method we use is the same as before. The only thing that needs to join the neural network is an extra dense layer, which takes the input vector as a representative of the current state.
The result of learning behavior
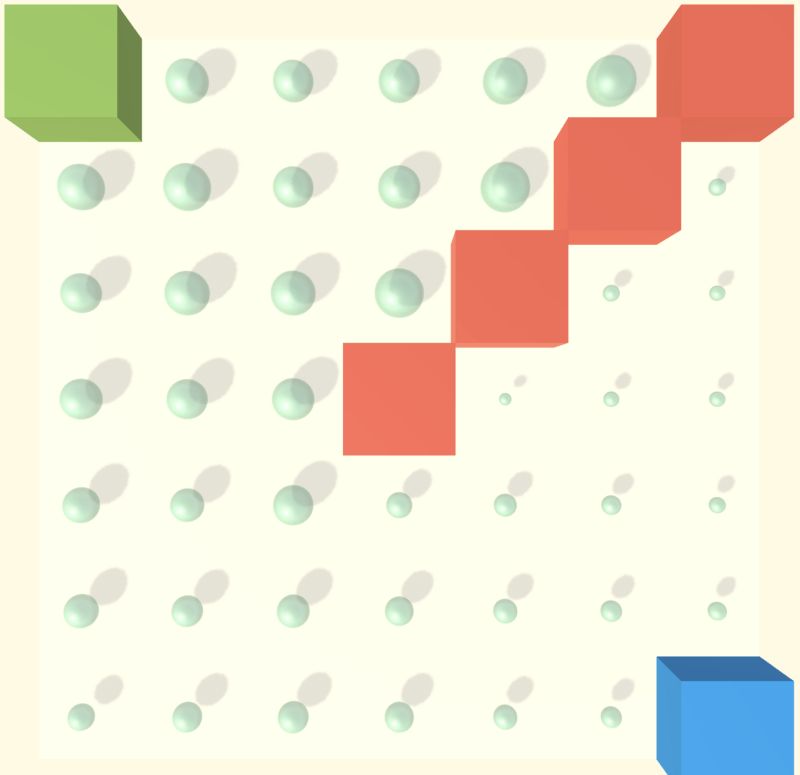
Here we learn how to move the blue cube so that it reaches the green cube without touching the red cube
There is also a key factor that can make our method simpler than other methods. In most environments, such as mazes, every step we take affects the surrounding environment. If you are traveling in the grid, you may be rewarded (or may not have anything), but in the next step we will be in a completely different state. This is the importance of the plan.
First, we will define the Q function as an immediate reward in the current state and a partial reward after the completion of all future actions. If the state of the Q estimate is accurate, then this method is useful, so we must first learn how to make a correct estimate.
We want to learn a good Q function using a method called Temporal Difference (TD) Learning. This method only focuses on recent walks. For example, TD(1) only uses the next two steps to evaluate the reward.
Surprisingly, we can get good results with the TD(0) that represents the current status and the evaluation of the next award. The structure of the network does not change, but we need to take the next step before committing an error, and then use this error to back-propagation the gradient, just like traditional deep learning, and then re-estimate the value.
Monte Carlo Introduction
Another way to predict the ultimate success is the Monte Carlo estimate. The method is to run all the possibilities under the current strategy to know the end, and then use this result to evaluate the status of each time. This allows us to spread the value effectively every time we move it, instead of simply moving it. This comes at the cost of introducing noise into the estimate.
Discrete environment

Previous methods used neural networks to approximate estimated values ​​and mapped some states and actions to values. For example, in the maze, there are 49 positions and 4 movements. In this environment, we try to learn how to keep the sphere in balance on the 2D plane. At each step we will decide in which direction the tablet will be tilted. The state space here is continuous, and the good news is that we can use neural networks to estimate the function.
The difference between off-policy and on-policy is inserted here: The method we used before was off-policy, that is, we can generate data from any strategy and learn from it. The on-policy method intelligence learns from actions. This limits our learning process because we must have an exploration strategy based on strategy, but we can directly bind the results to reasoning and let us learn more efficiently.
The method we will use here is called the strategy gradient, which is an on-policy method. Before, we first learned a value function Q and then built a strategy on it. In the Vanilla strategy gradient, we still use Monte Carlo estimates, but we learn strategies directly from the loss function, which increases the likelihood of selecting rewards. Because we are tactically learning, we cannot use a method such as greedy algorithm, we can only use a method called entropy regularization. It estimates the probability more widely and encourages us to make more bold choices.
Learn directly from the screen

The input pixel in the model
This is another benefit of using deep learning because deep neural networks excel at handling visual problems. When humans play games, the information we receive is not a series of states but an image.
Image-based learning combines convolutional neural networks and reinforcement learning. In this environment, we focused on the original image rather than the features, and added a 2-tier CNN to the network. We can even look at what the network will do when it generates values. In the following example, we can see that the network uses current scores and distant obstacles to predict the current value and use nearby obstacles to determine what action to take.

Here I noticed that deep learning is very sensitive to hyperparameters. For example, if you slightly adjust the discount rate, you will completely stop the learning of neural networks. This problem has become ubiquitous, but it is still very interesting to see with one's own eyes.
Subtle motion

So far, we have experimented in a decentralized and continuous state space, but each environment we studied has a decentralized motion space: we can move in four directions or tilt the board left and right. Ideally, for products like autopilot, we want to learn continuous movements such as turning the steering wheel. In this 3D environment, we can choose to tilt the board to any value, which also allows us to have more control over the action, but the action space is also greater.
The next step
The following are several concepts that distinguish between various algorithms:
Parallelizing: A3C is one of the most common methods. It adds an asynchronous step to the actor critic so that it can run in parallel. This allows it to solve more interesting problems within a reasonable time. The evolutionary approach can be further parallelized and performed very well.
Curriculum learning: In many cases, random operation may not receive any reward. This makes the exploration process very tricky because we can never learn anything of value. In this case, we can simplify the problem by first solving a simple version of the problem and then using the underlying model to solve the more complex environment.
Memory: For example, with LSTM, we can remember what happened in the past and then use the sequence to make decisions.
Model-Based Reinforcement Learning: There are several ways to help algorithms establish their learning environment model so that they can infer how the environment works, and at the same time only use simple actions to get higher rewards. AlphaGo combines models and plans.
At this point, my summary is over and I hope you find it useful! If you want to learn more about reinforcement learning. Editor's note: The author of this article is Emmanuel Ameisen, an expert specializing in machine learning and data science. He shared his understanding of deep learning on his blog and explained the basic concepts of deep learning in a concise manner.
Crystal Clear Back Sticker,Phone Sticker,Mobile Phone Back Skin,Crystal Clear Phone Skin
Shenzhen Jianjiantong Technology Co., Ltd. , https://www.jjthydrogelmachine.com