![<?echo $_SERVER['SERVER_NAME'];?>](/template/twentyseventeen/skin/images/header.jpg)
Long short-term memory network (LSTM) is a loop structure widely used in sequence modeling. LSTM uses a gate structure to control the amount of information transmitted in the model. But in actual operation, the doors in LSTM are usually in a "half open and half closed" state, which does not effectively control the memory and forgetting of information. To this end, the machine learning team of Microsoft Research Asia proposed a new LSTM training method, which makes the gate of the model close to "binarization"-0 or 1, which can remove or add information more accurately, thereby improving the accuracy of the model Performance, compression ratio and interpretability.
In many practical scenarios, deep learning models have to face the problem of unfixed input length or variable-length input: for example, in text discrimination, we need to judge whether the semantics of a sentence is positive or negative. Here The length of the input sentence is diverse; in the time series forecasting problem, we need to predict the current value based on the changes in the historical information, and the length of the historical information is also different at different points in time.
Ordinary neural network models, such as convolutional neural networks (CNN), cannot solve this type of input length problem. For this reason, people first proposed the Recurrent Neural Network, or RNN for short. The core of the cyclic neural network is to continuously integrate historical information and current information through a cyclic method. For example, when you watch episode N of a US drama, you need to update your understanding of the drama through the understanding (memory) of the plot of the previous N-1 episodes and the plot of the current episode (current input).
In the early days of deep learning, the RNN structure has been successful in many applications, but at the same time, the bottleneck of this simple model is constantly emerging, which not only involves the optimization itself (such as gradient explosion, gradient disappearance), but also the complexity of the model The problem. For example, the sentence "Xiao Zhang has eaten, how about Xiao Li?" This sentence is asking "Has Xiao Li eaten", but from the perspective of RNN, information flows in continuously from left to right, so In the end, it is difficult to tell whether you are asking Xiao Zhang if he has eaten or whether Xiao Li has eaten. So a new structure with forgetting mechanism was born-Long Short Term Memory Network (LSTM).
LSTM is a special type of RNN proposed by Hochreiter & Schmidhuber in 1997, which can learn long-term dependency information. In many natural language processing problems and reinforcement learning problems, LSTM has achieved considerable success and has been widely used.
The core composition of LSTM
The key component of LSTM is a structure called "gate". LSTM removes or adds information through a carefully designed gate structure. A door is a way of letting information through. In general, in a dimension, a gate is a value with an output range between 0 and 1, which is used to describe how much information in this dimension can pass through this gate-0 means "no amount is allowed to pass", 1 means "all passed."
LSTM has three types of gates, namely input gates, output gates, and forget gates.
First, LSTM needs to decide what information should be discarded from the history through the forget gate. In each dimension, the Forgotten Gate will read historical information and current information, and output a value between 0 and 1. 1 means that the historical information carried by this dimension is "completely retained", and 0 means the historical information carried by this dimension "Completely discard." For example, in the previous example, when we read "Xiao Zhang has eaten, how about Xiao Li?", we will forget Xiao Zhang in the "subject" message. This operation is achieved through the forget door.
Then, it is necessary to determine what new information needs to be stored in the current content. For example, in the previous example, after we "forget" Xiao Zhang, we need to change the subject information to Xiao Li. This "add" operation is realized through the input gate. . For different tasks, we need to organize and output current information to facilitate decision-making. This process of collating and outputting information is implemented through output gates. LSTM is shown on the right in the figure below.
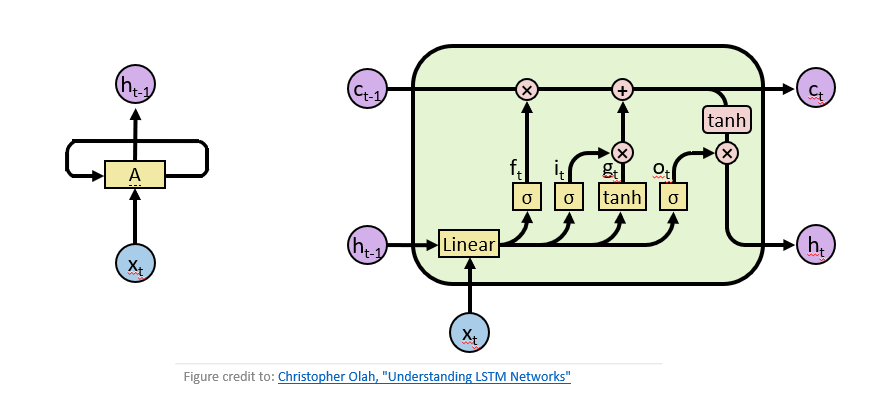
Figure 1 Left: Classic Recurrent Neural Network, Right: Long and Short Term Memory Network
In actual operation, the gate is realized by the activation function: given an input value x, through sigmoid transformation, a value in the range of [0,1] can be obtained. If x is greater than 0, the output value is greater than 0.5, if x is less than 0, the output value is less than 0.5.
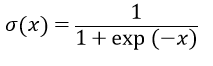
How effective is the "door" in practice?
Does the door really have the meaning we described above? This is also the starting point of our paper. To explore this problem, we analyzed the German-English translation task of IWSLT14. The model of this translation task is based on the sequence-to-sequence structure of LSTM.
We randomly selected 10,000 pairs of parallel corpora from the training set, and plotted the value distribution histograms of the LSTM input gate and forgetting gate on these corpora, as shown in the figure below.
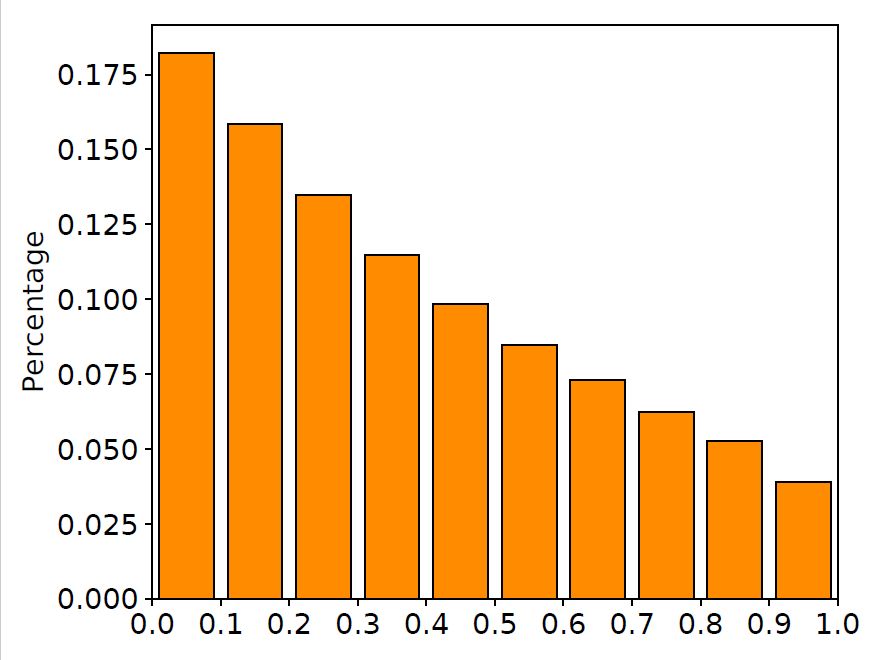
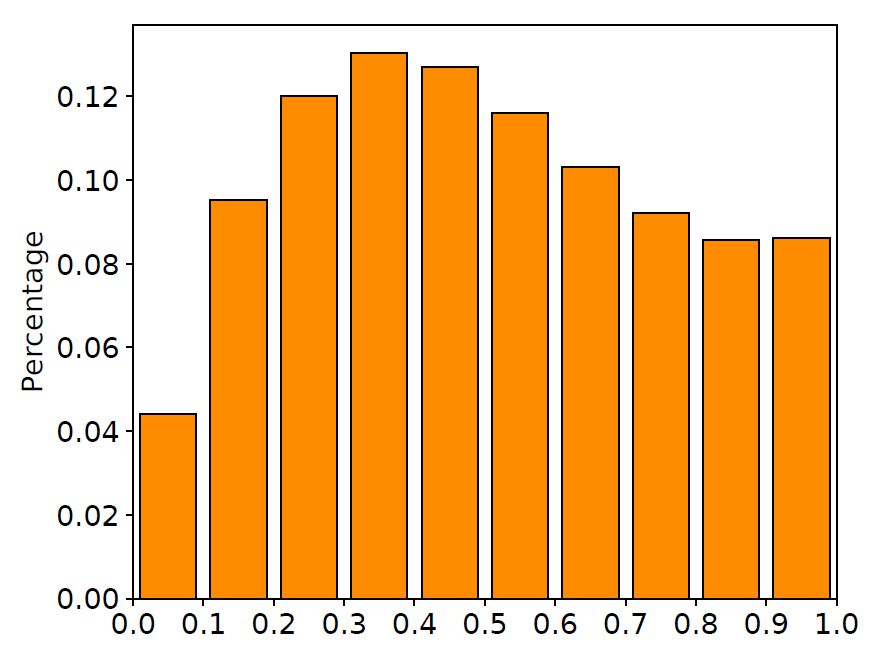
Figure 2 Value distribution of input gate and forget gate
It can be clearly seen from the figure that a large part of the gate values ​​are around 0.5. In other words, the doors in LSTM are in an ambiguous "half open and half closed" state. This phenomenon is different from the design of the LSTM network: these gates do not explicitly control the memory and forgetting of information, but "remember" all the information in some way. At the same time, many works have pointed out that most of the gates in LSTM are difficult to find practical meaning, which further confirms our findings (see the paper at the end of the article for related discussions).
"Binary" door structure
As can be seen from the above example, although LSTM has achieved good results in the translation task, the gate does not have the obvious effect as imagined. At the same time, some previous work pointed out that most dimensions of LSTM have no obvious interpretable information. So how can we learn a better LSTM? This question leads us to explore the greater value of the door structure: since the door is a concept of a switch, is it possible to learn a LSTM that is close to "binary-valued"? A binary-valued gate (binary-valued gate) has the following advantages:
1. The role of a door is more in line with the concept of a door in its true sense: in a general sense, a door actually refers to its two states: "open" and "closed". And our goal of learning a door close to "binarization" is also very consistent with the core idea of ​​LSTM.
2. "Binarization" is more suitable for model compression: If the value of the gate is very close to 0 or 1, it means that the input value x of the sigmoid function is a large positive number or a small negative number. At this time, the small change of the input value x has little effect on the output value. Since the input value x is usually also parameterized, "binarization" can facilitate the compression of this part of the parameters. Through experiments, we found that even if a large compression ratio is achieved, our model still has a good effect.
3. "Binarization" brings better interpretability: requiring the output value of the gate to be close to 0 or 1, which will have higher requirements for the model itself. In the process of information selection, a node retains or forgets all the information of that dimension. We believe that the door obtained by this kind of learning can better reflect the structure, content and internal logic of natural language, such as the example of eating mentioned earlier.
How to make the gate of the trained model close to binarization? We draw lessons from a new development in ICLR17 on the variational method: Categorical Reparameterization with Gumbel-Softmax. To put it simply, the best way to "binarize" the output of the gate is to train a stochastic neural network, where the output of the gate is a probability p, and a random sampling of 0/1 is obtained in the Bernoulli distribution , To get the loss when the different positions are 0/1, and then optimize the parameters to get the optimal p. When performing discrete operations on hidden layer nodes, gradient return encounters problems. The method we use is to approximate the probability density function of the multinomial distribution with Gumbel-Softmax Estimator, so as to achieve the purpose of both learning and convenient optimization (specific method See the paper at the end of the article). We named this method Gumbel-Gate LSTM, or G2-LSTM for short.
Accuracy, compressibility and interpretability
We tested this method on two classic applications of LSTM network-language model and machine translation, and compared it with the previous LSTM model in terms of accuracy, compressibility and interpretability.
Accuracy
Language model is one of the most basic applications of LSTM network. The language model requires the LSTM network to accurately predict the selection of the next word based on the previously known words in a sentence. We use the widely used Penn Treebank data set as the training corpus, which contains a total of about one million words. Language models generally use perplexity as an evaluation index. The smaller the perplexity, the more accurate the model. The experimental results are shown in the figure below.
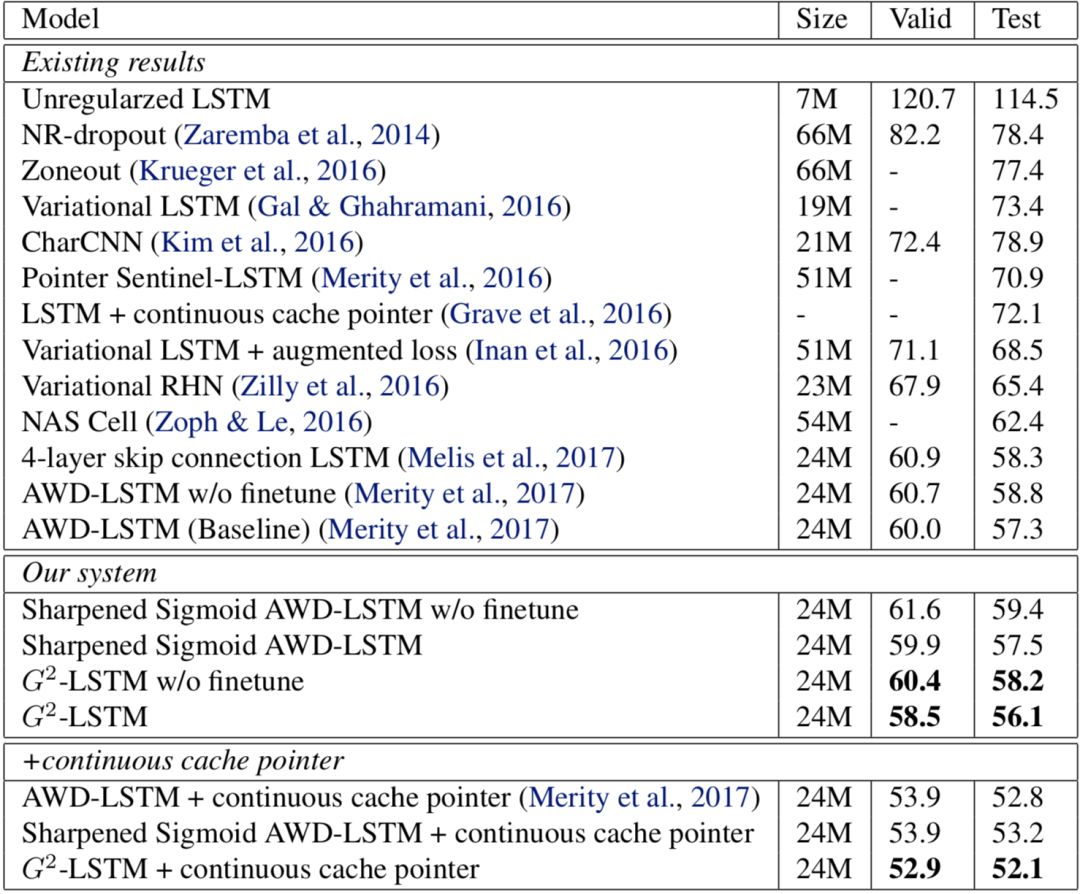
Figure 3 Language model experiment results
As can be seen from the figure, by "binarizing" the gates in the LSTM, the performance of the model has improved: the perplexity of our model is 56.1, which is an improvement of 1.2 compared with the perplexity 57.3 of the baseline model. With the addition of test-time post-processing (continuous cache pointer), our model reached 52.1, which is an improvement of 0.7 compared to the baseline model's 52.8.
Machine translation is currently one of the most successful areas of deep learning applications, and the LSTM-based end-to-end (sequence-to-sequence) structure is a widely used structure in machine translation. We tested our method on two public data sets: IWSLT14 German to English data set and WMT14 English to German data set. The IWSLT14 German-English data set contains about 150,000 sentence parallel corpus, and the WMT14 English-German data set contains about 4.5 million sentence parallel corpus. For the IWSLT14 German-English data set, we used a two-layer encoder-decoder structure; and due to the larger size of the WMT14 English-German data set, we used a larger three-layer encoder-decoder structure. Machine translation tasks generally use the BLEU value on the test set as the final evaluation criterion. The higher the BLEU value, the higher the translation quality. The experimental results of machine translation are shown in the figure below.
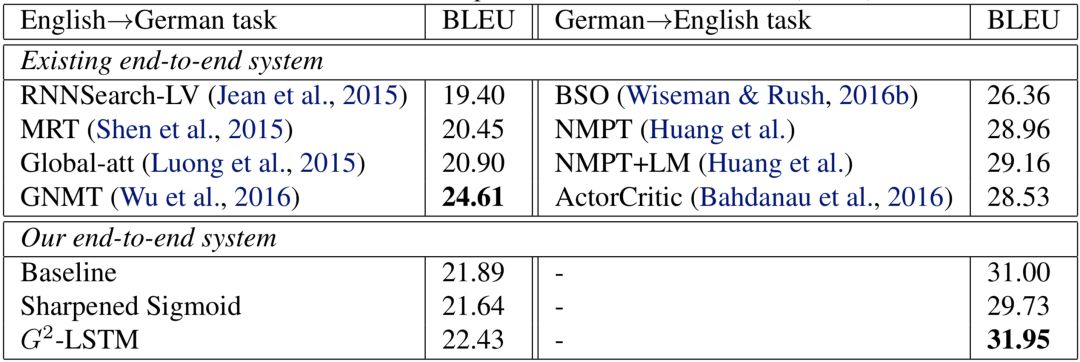
Figure 4 Machine translation experiment results
Similar to the experimental conclusions of the language model, the performance of our model on machine translation has also been improved: on the IWSLT14 German-English data set, the BLEU value of our model reached 31.95, which is 0.95 higher than the baseline model; while in WMT14 German-English On the data set, the BLEU value of our model is 22.43, which is 0.54 higher than the baseline model.
Compressibility
"Binarization" of the model can make our model more robust to parameter disturbances. Therefore, we compared the performance of different models under parameter compression. We used two methods to compress the parameters related to the door:
Precision compression. We first limit the accuracy of the parameters (using the round function). For example, when the r in the formula is 0.1, all model parameters are only retained to one decimal place. After that, we further controlled the range of parameter values ​​(using the clip function), and changed all parameters with a value greater than c to c, and changed all parameters with a value less than -c to -c. Since the parameter value ranges of the two tasks are not the same, in the language model, we set r=0.2 and c=0.4; in machine translation, we set r=0.5 and c=1.0. This makes all the parameters eventually only take 5 values
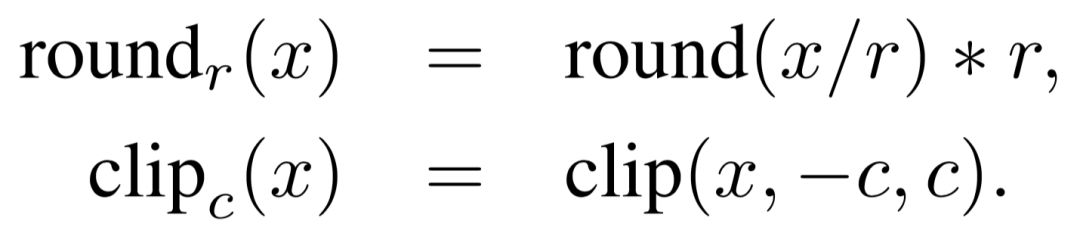
Low rank compression. We use singular value decomposition to decompose the parameter matrix into the product of two low-rank matrices, which can significantly reduce the model size and speed up the matrix multiplication, thereby increasing the speed of the model.
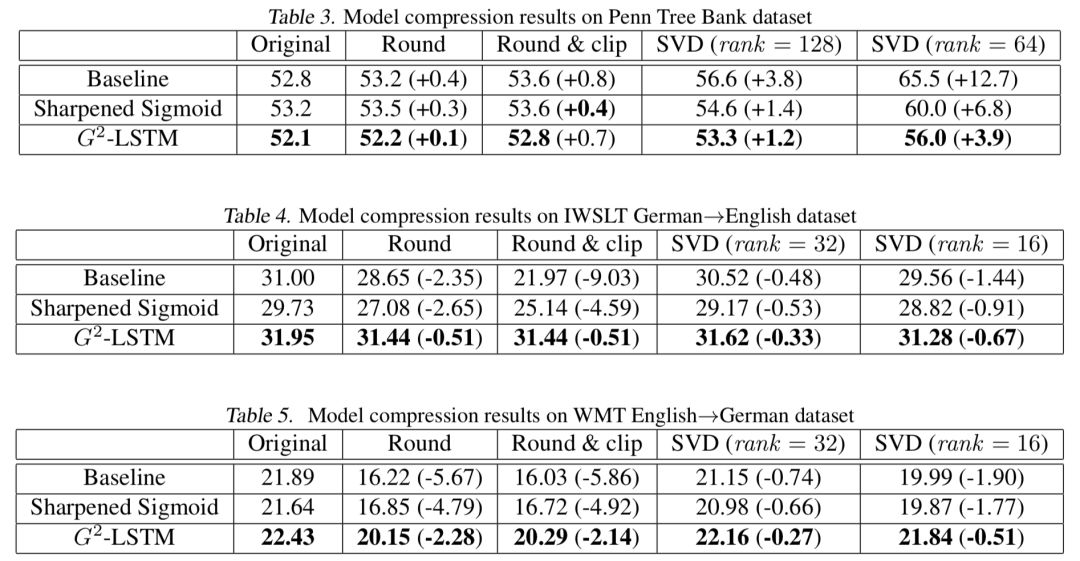
Figure 5 Experimental results after compression
The specific experimental results are shown in the figure above. We can see that in any case, our model is significantly better than the compressed model, which shows that the robustness of this model is greatly improved compared to the previous LSTM.
Interpretability
In addition to comparing the results of numerical experiments, we further observed the values ​​of gates in the model, and used the same corpus to draw a histogram of the value distribution of gates in our model, as shown in the figure below.
Figure 6 Value distribution of input gate and forget gate
We can see from the figure that most of the input gate values ​​are around 1.0, which means that our model accepts most of the input information; and the values ​​of forgetting gates are concentrated around 0.0 or 1.0, which means The forgetting door we got after training did achieve selective memory/forgetting information. These observations prove that our training algorithm can indeed make the value of the gate closer to the 0/1 ends.
In addition to observing the distribution of gate values ​​in the network on the data set, we also observed the average gate value at each moment on several sentences randomly selected from the training set, as shown in the following figure.
Figure 7 Sample analysis
From the figure, we can see that the input gate value of the traditional LSTM network is relatively average, and for some meaningful words (such as "wrong"), the average input gate value of the traditional LSTM network is small, which is not conducive to the model Obtaining information about this word will eventually make the model produce a bad translation effect. In our model, the value of the input gate is very large, which means that most of the word information is accepted by the LSTM network. On the other hand, in our proposed model, the words with a small forgetting gate value are some functional words, such as conjunctions ("and") or punctuation, which shows that our model can correctly determine the boundary of the sentence to clear it. The previous memory of the model to obtain new information.
For more details, please visit the link below or click to read the original text to visit our paper:
Zhuohan Li, Di He, Fei Tian, ​​Wei Chen, Tao Qin,Liwei Wang, and Tie-Yan Liu. "Towards Binary-Valued Gates for Robust LSTM Training." ICML 2018.
Link to the paper: https://arxiv.org/abs/1806.02988
About the Author:

Li Zhuohan, a 2015 undergraduate from the School of Information Science and Technology, Peking University, is an intern in the machine learning group of Microsoft Research Asia. The main research direction is machine learning. Mainly focus on the design of deep learning algorithms and their applications in different task scenarios.
When people talk about 7inch tablet, kids appears on their minds, especially for elementary students or kindergarten kids for playing intelligent exploitation games or online learning. Clients usually choose 7 inch tablet wifi only as 7 inch educational tablet for project, wifi one is much cheaper. Of course, 7 inch Android Tablet with 3G lite or 4G lite also optional. You can always see a right tablet at this store, no matter amazon 7 inch tablet, 8 inch android tablet, or 10.1 android tablet.
Except android tablet and window tablet, there are Education Laptop, Mini PC , All In One PC, which are is the main series at this store. Any other special configuration interest, just email or call us, you will receiving value information in 1-2 working days.
To meet clients` changing requirements, we contributes 10-20% profit to develop new designs according market research and client`s feedback.
So you are always welcome if can share your special demand or your clients opinion for the products.
7 Inch Tablet,7 Inch Android Tablet,Amazon 7 Inch Tablet,7 Inch Tablet Wifi Only,7 Inch Educational Tablet
Henan Shuyi Electronics Co., Ltd. , https://www.shuyiminipc.com