![<?echo $_SERVER['SERVER_NAME'];?>](/template/twentyseventeen/skin/images/header.jpg)
True heroes, famous in Shaolin Temple Martial Arts Congress; good algorithm to verify public data in Stanford.
A fair and influential platform in the martial arts novels can make the big man come to the fore. Scientific research is also a good public data set can make a good algorithm come to the fore, and at the same time make those who rely on blown algorithm be ruined. This article will describe in detail the SQuad, the most important data set of the natural language processing industry so far this year.
1. What is SQuAD?
SQuAD is a data set released by Stanford University in 2016. A reading comprehension data set, given an article, prepares the corresponding questions and requires the algorithm to give answers to the questions. All articles in this dataset are selected from Wikipedia, and the amount of datasets is several-tenths of that of other datasets such as WikiQA. There were a total of 107,785 issues and an accompanying 536 articles. The contributors to the data set are Stanford Percy Liang et al., who is an all-round talent in the natural language processing community and has significant contributions in many fields such as Semantic Parsing, QA, and Optimization.
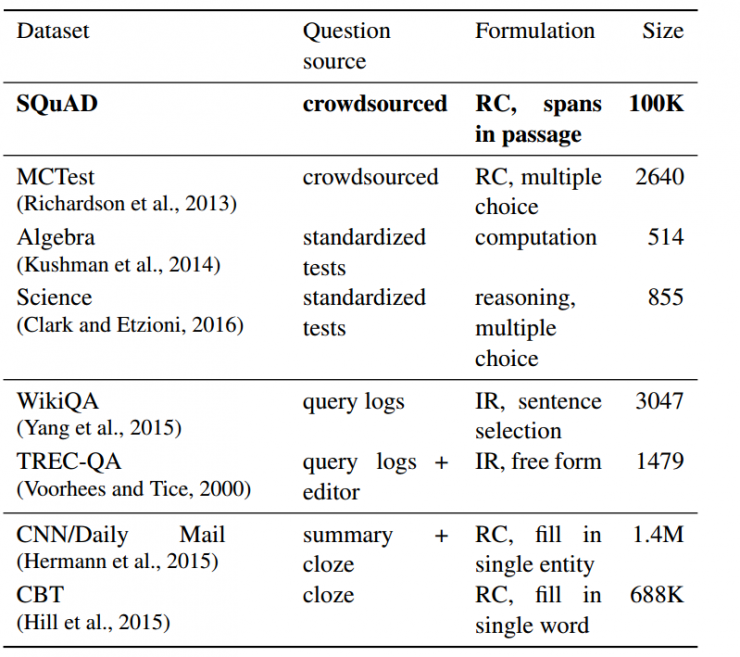
The current public dataset comparison is as follows: MCTest, Algebra and Science are the three publicly available reading comprehension datasets. We can see that Squad far exceeds these three datasets in number, which makes it possible to train on this dataset. Large-scale complex algorithms become possible. At the same time, Squad also far exceeds the number of famous Q&A datasets, WikiQA and TrecQA. While CNN Mail and CBT are large, both datasets are datasets for guessing words, and are not really question and answer.
2. Catch up with ImageNet and force automatic question and answer
This dataset article demonstrates Stanford's ambition to be a natural language processor for ImageNet. He is likely to become the most popular dataset in natural language academia for at least one year in the future. The model's good results on this data set can make a lot of points for its own articles, and the chances of being accepted at the top are greatly increased. If readers want to summit, and there is no clear direction for research at the moment, then it is a good way to brush this data set.
At the same time, this data set will also contribute to the industry. The reason is that it will contribute to the industry because the research atmosphere of natural language processing is worse than the image, the task is more, and there is no industry rule that attaches code in the paper, resulting in a lot of work cannot be reproduced, and even some people Will not even do experiments, directly fill in figures and tables to create an article. This dataset learns Imagenet and doesn't give test sets, so you can't cheat, hand over the code, I'll give you a run, and then evaluate the level of the test set, so that everyone is fair, and no one will brag. , who do not cheat. This type of environment is conducive to the emergence of truly significant contributions. For example, the Residual Network swept the image field last year. In a fair environment, it was presented to the world with much better results than other competitors. SQuAD, on the other hand, is Stanford's natural language processing. It intends to build a test set similar to "ImageNet". Scores are displayed on the leaderboard in real time.
This gives this dataset the following advantages:
Tested a really good algorithm. Especially for the industrial world, this dataset is very worthy of attention, because he can tell everyone now how each algorithm ranks on the task of “reading comprehension†or “auto answeringâ€. We can just look at the score ranking to know which algorithm in the world is the best. We will no longer doubt whether the author has done something wrong or it is wrong.
Provide a large-scale data set for reading comprehension. Because the previous reading comprehension data set is too small or very simple, an ordinary deep learning algorithm can be used to brush to 90%, so it does not reflect the pros and cons of different algorithms.
Even if SQuAD doesn't have as much influence as ImageNet, it will definitely have a far-reaching impact on the QA area in the next few years, and it will be a battleground for major giants in the area of ​​automated question and answer. IBM has already started).
3. How to build SQuad dataset?
Next, let's detail the construction of this data set (this data set has been included in the EMNLP2016 conference at https://arxiv.org/pdf/1606.05250.pdf). Let's take a look at the beautiful interface of this data set.

From the figure we can see that in the validation set and test set level. The test collection requires you to submit a program that can run. The last one and the first one are the baseline that the author did and the level that people can answer. We can see that although only one month was released, some universities and IBM companies in Singapore have already tried this task. The following figure is an example of this data set. First, give an article, and then begin to ask questions. The first question “What caused rainfall†is caused by gravity. The problem is very difficult and requires reasoning, but the answer still appears in the text.

The specific construction of the data set is as follows
1. The article is a random sample wikipedia with a total of 536 wikis selected. Each wiki is cut into paragraphs, and finally, 23,215 natural segments are generated. Afterwards, they read comprehension of the 23,215 natural segments, or auto answer questions.
2. After Stanford, using crowdsourced methods, given articles, asked questions and manually annotated the answers. They gave more than twenty thousand paragraphs to different people and asked five questions for each paragraph.
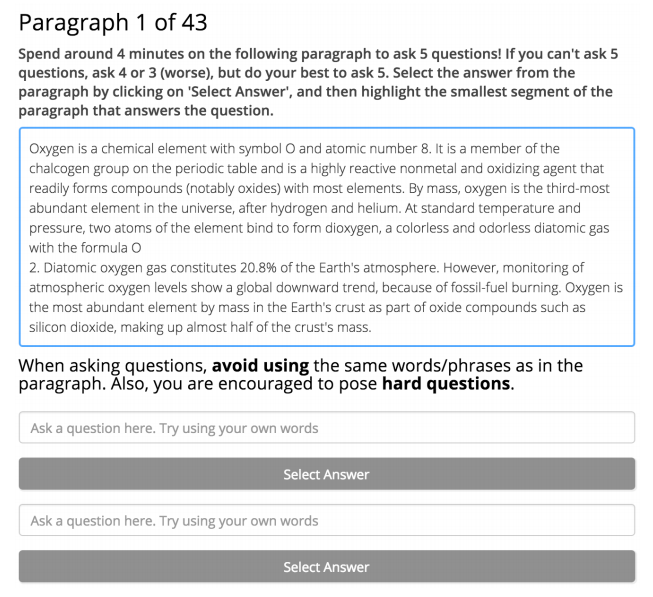
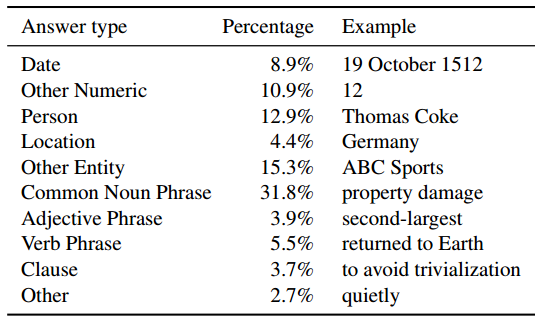
3. Let other people give the shortest segment of the article the answer to this question. If not, or if the answer does not appear in the article, it cannot be given. After their verification, the issues raised by the people are quite diverse in the distribution of the types of problems, and there are many problems that need reasoning, which means that the collection is very difficult. As shown in the figure below, the author lists the distribution of the answers to the data set. We can see that the dates, names, locations, and figures are all included and the proportions are equal.
4. There are two evaluation criteria for this data set. First: F1, second: EM. EM is an abbreviation of exact match and must be given by the machine as it is given by the person. Even if one letter is different, it will be wrong. And F1 is to cut the phrase of the answer into words, and count with the person's answer recall, Precision and F1, that is, if you match some words but not all right, still count points.
5. For this dataset, they also made a baseline by combining features with an LR algorithm to finally reach 40.4 for em and 51 for f1. Now IBM and Singapore Management University use the deep learning model to break through this algorithm. It can be imagined that more people will challenge reading comprehension in the near future and natural language heroes will also be born. There are even algorithms that exceed human accuracy.
Automatic question and answer beyond humans, are you ready?