![<?echo $_SERVER['SERVER_NAME'];?>](/template/twentyseventeen/skin/images/header.jpg)
Introduction
Google’s self-driving cars and robots have captured a lot of media attention, but the real future of the company lies in machine learning—a technology that makes computers smarter and more personalized. As Eric Schmidt, Google's Chairman, once said.
We are living in one of the most transformative periods in human history, from the era of mainframes to personal computers and now cloud computing. What makes this time truly meaningful is not just what has happened, but how we will shape the next few years.
This period has sparked my excitement about the democratization of tools and technology through computing. Today, as a data scientist, I can build complex data processors with advanced algorithms in just a few hours. But getting here wasn’t easy—there were many long nights and tough challenges along the way.
Who stands to benefit most from this guide? I believe what I’ve shared today is among the most valuable resources I’ve ever created.
The purpose of this guide is to simplify the journey for aspiring data scientists and machine learning enthusiasts worldwide. It aims to help you gain hands-on experience while studying machine learning problems. I have a strong understanding of various machine learning algorithms, along with R and Python code implementation, which should be more than enough to get you started comfortably.

I deliberately omitted the statistical foundations behind these techniques because they aren't necessary at the beginning. If you're looking for a deep statistical understanding, there are other articles for that. However, if you're ready to start building your own machine learning projects, this guide will be incredibly helpful.
Class 3 Machine Learning Algorithms (in a broad sense)
Supervised Learning
How it works: This type of algorithm uses a set of target or dependent variables to predict outcomes based on input features. By analyzing these variables, we create a function that maps inputs to desired outputs. The model is trained until it achieves the required level of accuracy. Examples include regression, decision trees, random forests, KNN, and logistic regression.
Unsupervised Learning
How it works: Unlike supervised learning, there are no predefined target variables. Instead, the algorithm identifies patterns and groups data into clusters. For instance, it can be used to segment customers into different categories. Common examples include the Apriori algorithm and K-means clustering.
Reinforcement Learning
How it works: In this approach, the machine learns by interacting with an environment, using trial and error. It builds knowledge over time to make better decisions. An example is the Markov Decision Process, where the system learns optimal actions through repeated experiences.
Common Machine Learning Algorithms
Here is a list of commonly used machine learning algorithms that can be applied to almost any data problem:
- Linear Regression
- Logistic Regression
- Decision Tree
- SVM
- Naive Bayes
- KNN
- K-Means
- Random Forest
- Gradient Boosting & Adaboost
Linear Regression
Linear regression is used to estimate actual values, such as house prices, number of calls, or sales figures, based on continuous variables. It establishes a relationship between independent and dependent variables by fitting the best possible line, known as the regression line, represented by the equation Y = a * X + b.
To understand linear regression, imagine a child being asked to sort classmates by weight without knowing their actual weights. The child might use height and body size as visual indicators, essentially performing a real-life version of linear regression. This process reflects the idea that certain factors (like height) correlate with another (weight), similar to the equation above.
In the equation:
- Y = Dependent variable
- a = Slope
- X = Independent variable
- b = Intercept
These coefficients are calculated by minimizing the sum of squared differences between the observed data points and the regression line.
For example, the best fit line for the equation y = 0.2811x + 13.9 allows us to predict a person’s weight based on their height.
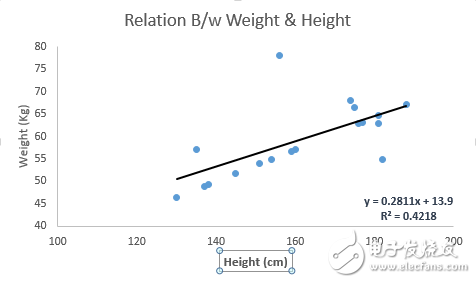
There are two main types of linear regression: simple and multiple. Simple linear regression involves only one independent variable, while multiple linear regression uses more than one. Additionally, polynomial regression can be used to fit curves instead of straight lines when appropriate.
Anyang Kayo Amorphous Technology Co.,Ltd is located on the ancient city-Anyang. It was founded in 2011 that specializes in producing the magnetic ring of amorphous nanocrystalline and pays attention to scientific research highly,matches manufacture correspondingly and sets the design,development,production and sale in a body.Our major product is the magnetic ring of amorphous nanocrystalline and current transformer which is applied to the communication, home appliances, electric power, automobile and new energy extensively. We are highly praised by our customers for our good quality,high efficiency,excellent scheme,low cost and perfect sale service.
Fe-based amorphous Ribbon is an ultra-fine grain structure that has high permeability,high saturation magnetic induction,low loss and excelent stability. It can satisfy the requests of electronical products which is high frequency,large current,small volume and energy-saving.Especially it can replace the silicon steel,permalloy and ferrite and be used to all kinds of electronical products widely.
Amorphous Ribbon,Fe-Based Amorphous Ribbon,Low-Cost Amorphous Ribbon,Custom Fe-Based Amorphous Ribbon
Anyang Kayo Amorphous Technology Co.,Ltd. , https://www.kayoamotech.com