![<?echo $_SERVER['SERVER_NAME'];?>](/template/twentyseventeen/skin/images/header.jpg)
FPGA-based universal CNN acceleration design significantly reduces the development cycle of FPGAs, supports rapid iteration of deep learning algorithms, and offers computing performance comparable to GPUs. However, it has a clear advantage in terms of latency over GPUs, making it the strongest solution for real-time AI service capabilities.
**When? The Status of Heterogeneous Computing in Deep Learning**
With the rapid growth of internet users and the exponential increase in data volume, the demand for computing power in data centers is rising sharply. At the same time, computationally intensive fields such as artificial intelligence, high-performance data analysis, and financial analytics have far exceeded the capabilities of traditional CPU processors.
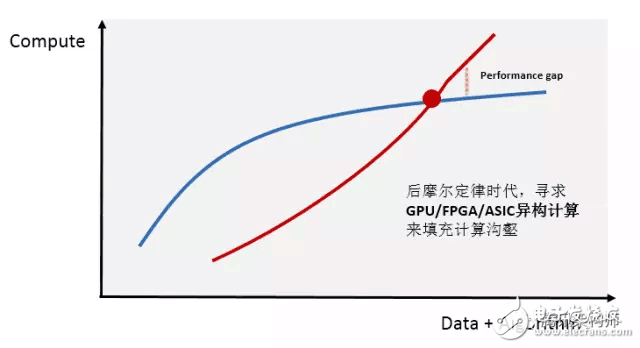
Heterogeneous computing is now seen as a key technology to bridge this gap. The most popular platforms currently are "CPU+GPU" and "CPU+FPGA," both offering higher efficiency and lower latency compared to traditional CPU-based parallel computing. With such a massive market potential, many tech companies have invested heavily in research and development. Heterogeneous programming standards are gradually maturing, and major cloud service providers are actively integrating these technologies into their infrastructures.

**Why? The Advantages of General CNN FPGA Acceleration**
Major companies like Microsoft have already deployed large-scale FPGAs for AI inference acceleration. What makes FPGAs stand out compared to other devices?
- **Flexibility**: FPGAs are programmable and can naturally adapt to the fast evolution of machine learning algorithms.
- **Support for Arbitrary Precision**: They can dynamically support different precision levels.
- **Model Compression & Sparse Networks**: Enable faster and more efficient network performance.
- **Performance**: Deliver real-time AI service capabilities.
- **Low Latency**: Offers prediction speeds orders of magnitude faster than GPU/CPU.
- **High Efficiency per Watt**: Provides superior performance per watt compared to GPU/CPU.
- **Scalability**: Supports high-speed interconnects between boards and integrates with Intel CPU-FPGA architectures.
However, FPGAs also face challenges. Development involves HDL languages, which leads to long cycles and high entry barriers. Custom development for models like AlexNet or GoogLeNet can take several months, creating pain points for both business teams and FPGA accelerators. To address this, we designed a universal CNN accelerator that allows for quick model switching through compiler-driven instruction generation. This reduces development time from months to just one or two weeks, keeping up with the fast-paced evolution of deep learning algorithms.
**How? A Generic CNN FPGA Architecture**
The overall framework of our universal CNN accelerator based on FPGA is as follows: Models trained using Caffe, TensorFlow, or MXNet generate optimized instructions via a compiler. Image data and model weights are preprocessed and compressed before being sent to the FPGA accelerator via PCIe. The FPGA executes the instruction set in its buffer, enabling efficient computation for deep learning models. Each module operates independently, handling specific tasks while maintaining control over data dependencies and execution order through the instruction set.
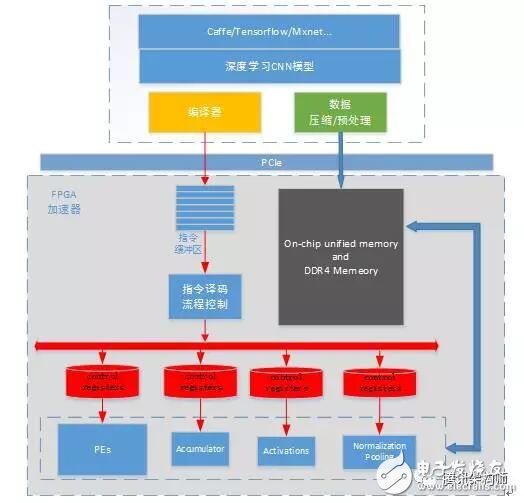
In simple terms, the compiler's main role is to analyze and optimize the model structure, generating an efficient instruction set for the FPGA. The optimization goal is to maximize MAC/DSP computational efficiency and minimize memory access requirements.
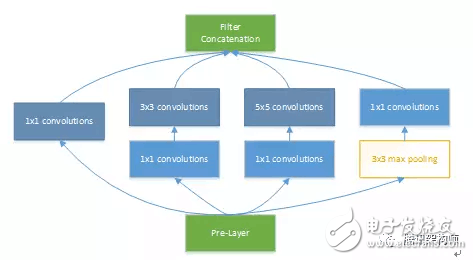
Let’s take GoogLeNet V1 as an example. This model combines 1x1, 3x3, 5x5 convolutions, and 3x3 pooling, enhancing network bandwidth and scalability. The figure below shows the basic structure of Inception modules within the model.
**Data Dependency Analysis**
This section focuses on identifying streamable and parallelizable operations in the model. Streamlined design improves the utilization of computing units, while parallelization maximizes the use of available resources.
Regarding pipelining, we analyze how data flows from DDR to SRAM on the FPGA and how the PE (Processing Element) performs calculations. Optimizing memory access times helps overlap them, improving DSP utilization.
For parallelism, we focus on the relationship between PE arrays and post-processing modules like activation, pooling, and normalization. Determining data dependencies and avoiding conflicts is crucial. In Inception, for instance, the 1x1 convolution in branches a/b/c and the pooling in branch d can be computed in parallel without data dependencies, allowing the 3x3 max pooling layer to be fully overlapped during optimization.
**Model Optimization**
Two main considerations guide the design:
1. **Model Structure Optimization**: Finding ways to simplify or enhance the model for better performance.
2. **Fixed-Point Support**: Enabling dynamic precision adjustment for better flexibility and efficiency.
These optimizations ensure that the FPGA accelerator can efficiently handle evolving deep learning models while maintaining high performance and low latency.
Dual-band Bandpass Filters (BPFs) provide the functionality of two separate filters, but in the size of a single filter. Dual band pass filter applications are at the leading edge of fiber optical modules and systems. Using DBPFs is a new concept in multiplex and de-multiplex module design used in optimizing wavelength ranges or channel management. The application of DBPFs makes it possible to reduce the component quantity in optical modules, enhances their performance, and enables faster data transfer in the optical backbone of major networks.
Dual Bandpass Filters,Visible Light Filter,Optical Filters Bandpass,Band Pass Filter
Changchun Realpoo Photoelectric Co., Ltd. , https://www.optics-realpoo.com