![<?echo $_SERVER['SERVER_NAME'];?>](/template/twentyseventeen/skin/images/header.jpg)
Introduction
Google’s self-driving cars and robots have captured a lot of media attention, but the true future of the company lies in machine learning—a technology that makes computers more intelligent and personalized. As Eric Schmidt, Google’s chairman, once said.
We are living in one of the most transformative periods in human history, from mainframes to personal computers, and now to cloud computing. What makes this era truly significant isn't just what has happened, but how we will shape the next few years through innovation and progress.
This era has excited me deeply because it has made powerful tools and technologies accessible to more people. As a data scientist today, I can build complex data processing systems with advanced algorithms in just a few hours. But getting here wasn’t easy—I spent many late nights and early mornings working through challenges and learning from failures.
Who will benefit the most from this guide? I believe what I’ve shared today is one of the most valuable resources I’ve ever created.
The purpose of this guide is to simplify the path for aspiring data scientists and machine learning enthusiasts around the world. It aims to help you gain hands-on experience while studying machine learning problems. I have a strong understanding of various machine learning algorithms and their implementation in R and Python, which should give you confidence as you start your journey.

I intentionally skipped the statistical details behind these algorithms since they aren’t necessary at the beginning. If you're looking for a deep statistical understanding, you might want to explore other resources. However, if you're ready to start building your own machine learning projects, this guide will be incredibly helpful.
Class 3 Machine Learning Algorithms (in a broad sense)
Supervised Learning: This type of algorithm works by using a set of target or dependent variables that are predicted based on independent variables. The goal is to create a function that maps inputs to desired outputs. The model is trained until it achieves the required level of accuracy. Examples include regression, decision trees, random forests, KNN, and logistic regression.
Unsupervised Learning: Unlike supervised learning, there are no predefined target variables. Instead, the algorithm identifies patterns and groups data into clusters. Common examples include the Apriori algorithm and K-means clustering.
Reinforcement Learning: In this approach, the machine learns by interacting with an environment and using trial and error. It improves over time by learning from past experiences and aiming to make optimal decisions. A classic example is the Markov Decision Process.
Common Machine Learning Algorithms:
Here is a list of widely used machine learning algorithms that can be applied to almost any data problem:
Linear Regression, Logistic Regression, Decision Tree, SVM, Naive Bayes, KNN, K-Means, Random Forest, Gradient Boosting, and Adaboost.
Linear Regression:
Linear regression is used to estimate actual values such as house prices, number of calls, or total sales based on continuous variables. It establishes a relationship between independent and dependent variables by fitting the best line, known as the regression line, represented by the equation Y = a * X + b.
To understand linear regression, imagine asking a child to sort classmates by weight without knowing their actual weights. The child would likely use visual cues like height and body size to estimate weight—this is essentially linear regression in action.
In the equation:
Y = dependent variable
a = slope
X = independent variable
b = intercept
The coefficients a and b are determined by minimizing the sum of squared differences between the data points and the regression line.
For example, the best fit line for the equation y = 0.2811x + 13.9 allows us to predict a person's weight based on their height.
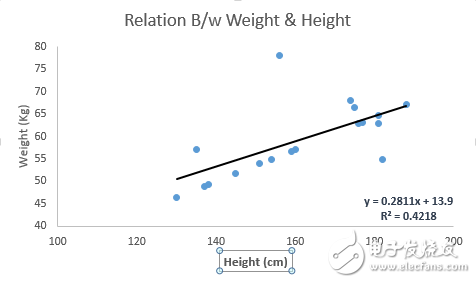
There are two main types of linear regression: simple and multiple. Simple linear regression involves one independent variable, while multiple linear regression uses more than one. You can also fit polynomial or curved regression lines when needed.
Custom Co-Based Amorphous Ribbon,New Type Nano Ribbon,Good Fe-Based Amorphous Ribbon,New Type Co-Based Ribbon
Anyang Kayo Amorphous Technology Co.,Ltd. , https://www.kayoamotech.com