![<?echo $_SERVER['SERVER_NAME'];?>](/template/twentyseventeen/skin/images/header.jpg)
FPGA-based universal CNN acceleration design significantly reduces the FPGA development cycle, supports rapid iteration of deep learning algorithms in business scenarios, and delivers computing performance comparable to GPU. Moreover, it offers a much lower latency compared to GPU, enabling the strongest real-time AI service capabilities for enterprises.
**When? Deep Learning Heterogeneous Computing Status**
With the rapid growth of internet users and the explosion of data volume, the demand for computing power in data centers has surged. At the same time, computationally intensive fields such as artificial intelligence, high-performance data analysis, and financial modeling have exceeded the capabilities of traditional CPU processors.
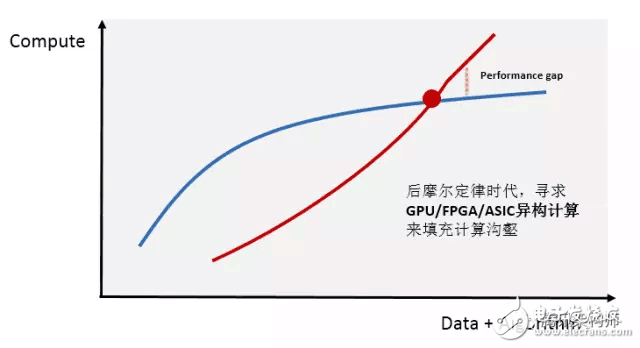
Heterogeneous computing is now considered the key technology to bridge this computing gap. Currently, the most popular platforms are "CPU+GPU" and "CPU+FPGA," which offer higher efficiency and lower latency than traditional CPU-based parallel computing. With a growing market, many tech companies have invested heavily in research and development, and standards for heterogeneous programming are gradually maturing. Major cloud service providers are also actively deploying these solutions.

**Why? General CNN FPGA Acceleration**
It's clear that big companies like Microsoft have deployed FPGAs at scale for AI inference acceleration. What makes FPGAs stand out over other devices?
- **Flexibility:** FPGAs are programmable and can naturally adapt to the fast evolution of machine learning algorithms.
- **Support for arbitrary precision and dynamic adjustment.**
- **Model compression, sparse networks, and faster network performance.**
- **Performance:** FPGAs offer low-latency prediction capabilities, orders of magnitude better than GPUs or CPUs.
- **Single-watt performance:** FPGAs deliver higher performance per watt compared to GPUs and CPUs.
- **Scalability:** High-speed interconnects between boards and Intel CPU-FPGA architectures.
However, FPGAs also have their limitations. Development involves HDL, which leads to long cycles and a high entry barrier. For example, custom development of models like AlexNet or GoogLeNet can take several months. This creates a challenge for businesses and FPGA teams to balance algorithm iterations with hardware acceleration.
To address these challenges, we designed a universal CNN accelerator. It uses a compiler-driven approach to generate instructions, allowing quick model switching. For new deep learning algorithms, we optimized the basic operators, reducing development time from months to just one or two weeks.
**How? Generic CNN FPGA Architecture**
The overall framework of our universal CNN accelerator based on FPGA is as follows: The trained CNN model from Caffe, TensorFlow, or MXNet generates optimized instructions via a compiler. Image data and model weights are preprocessed and compressed before being sent to the FPGA via PCIe. The FPGA accelerator executes these instructions in the instruction buffer, completing the computation of the deep learning model efficiently.
Each functional module operates independently, handling specific tasks. The accelerator is decoupled from the deep learning model, with data dependencies and execution order controlled through the instruction set.
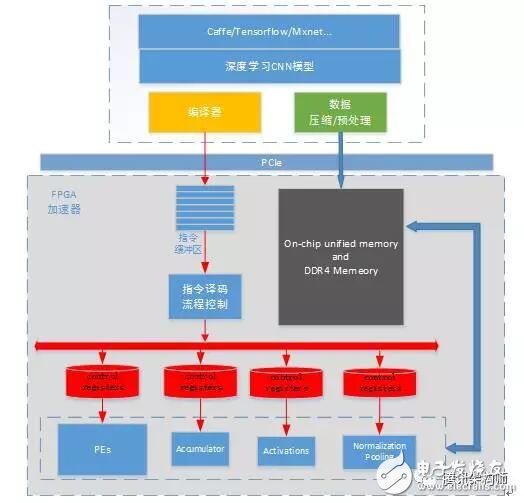
In simple terms, the compiler analyzes and optimizes the model structure to generate efficient instructions for the FPGA. The optimization goal is to maximize MAC/DSP computational efficiency while minimizing memory access.
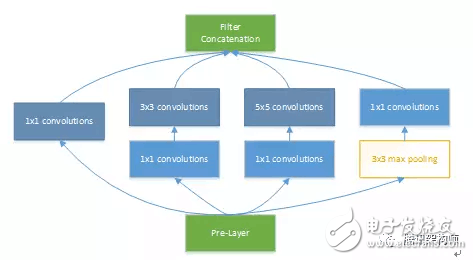
Let’s take the GoogLeNet V1 model as an example. This network combines 1x1, 3x3, 5x5 convolutions and 3x3 pooling, enhancing bandwidth and scalability. The figure below shows the basic structure of Inception modules.
**Data Dependency Analysis**
This section focuses on identifying flowable and parallelizable computations within the model. Streamlined design increases the utilization of computing units, while parallelization maximizes the use of available resources.
Pipeline analysis includes data loading from DDR to SRAM and processing by the PE (Processing Element). Optimizing memory access overlaps and ensuring efficient DSP utilization are key.
Regarding parallelism, we focus on the relationships between PE arrays and post-processing modules like activation, pooling, and normalization. Determining data dependencies and avoiding conflicts is critical. In Inception, for example, the 1x1 convolution in branches a/b/c and the pooling in branch d can be computed in parallel, with no data dependency. This allows us to fully overlap the 3x3 max pooling calculation.
**Model Optimization**
Two main considerations guide the design: optimizing the model structure and supporting fixed-point arithmetic for dynamic precision adjustments. These optimizations ensure efficient execution on FPGA hardware while maintaining accuracy and performance.
A concave grating has the advantage of setting up a spectroscopic system without any imaging optics like concave mirrors. For this reason, the concave grating is used in a wide range of applications, such as analytical instruments, optical communications, biotechnology, and medical instruments. Spectroscopes incorporating concave gratings are classified roughly into two categories: polychromators or monochromators. holographic concave gratings are recorded on spherical substrates, with equidistant and parallel grooves.
Holographic Concave Grating,Angle Of Diffraction Grating,Holographic Diffraction Grating,Ruled Grating
Changchun Realpoo Photoelectric Co., Ltd. , https://www.optics-realpoo.com